這篇心得是應之前python spark decision tree 的老師Mercel Wang邀約所寫的,不過我也不清楚怎麼寫才適合,所以就先交待一下那門課的狀況吧.當時他是在FB的python Taiwan開了一個關於spark和決策樹的討論串,我當時剛好也好奇machine learning到底在幹嘛,就跟著討論串+1.
這門課以交作業的方式進行,當有人貼出該次作業後,就繼續發放下一週的作業,前幾個禮拜都要搜集和消化不少資料和文獻,不過好處是如果不知道作業怎麼寫,也能參考其他先做出來的人的作品,這門課對上班族來說負擔不算輕,得在下班和假日處理作業的事情,不過也因此從完全不知道ML是什麼東西的人,變成能夠講述ML大概是怎樣的東西.
不過我比較沒定力,從作業9之後,就沒再繼續了,一個是老師沒繼續出作業就懶得繼續下去,另一個是工作和生活上碰不到需要Hadoop的情境,加上hadoop/spark/scala的版本真是一團亂,所以一整個發懶.時間推移到今年三月,我在公司建構機聯網,蓋到一半突然想到用ML來判斷製程的參數到底好或壞,也許是好玩又可行的案子,因此又重新把之前看過的文獻和資料找了出來.
本來我是想說用現成的lib就好,但是沒想到公司的網路完全把python lib wheel擋起來,我又很懶得研究如何翻牆,於是就想說來看看這些lib的原始碼怎麼寫的好了~原本不看還好,看過才發現,「我根本看不懂他們在寫啥...」想說這樣不行,這樣根本寫不出東西呀!
我想了想,決定還是用最笨的方法好了,從數學方法一步步來蓋自己看得懂的ML(反正工控和製程的數據壓根稱不上“大”數據,一天有個2GB就不錯了,因此效率就不是我的首要考量),由於在工業控制和機械領域,C#是王道(c/c++是大神級玩的,小的玩不起),所以就以C#來撰寫,首先是以類神經網路開刀,花了個半天寫了個最初級的感知器,就覺得其實也不難嘛~哈哈!我就串了十幾個一樣的感知器來跑iris data來玩,感覺還ok.隔天就來挑戰SVM.結果發現我想得太單純了,這個有夠難懂.
SVM網路的資料非常非常非常非常的多,但是能夠把數學方法解釋得詳細的沒幾個,甚是錯誤不少,比如說向量和純量的表示法搞錯,符號定義不明,亂用之類的(暈).暈了幾天後,總算找到一個非常淺顯易懂的教材,MIT的machine learning課程[1],用它教學的步驟總算把一個可以二分類的SVM蓋起來了,分類的邏輯搞定,但是需要大量的矩陣運算,因此在一個禮拜內惡補了不少線性代數的東西(以前只有大二修過工程數學,有講到半個學期的線代,但早還給教授了,畢竟她研究有需要用到,她要用的時候沒有會很困擾的),總算蓋了一個高斯消去運算器來處理矩陣,不過實際跑的時候發現,遇到[20*20]以上的矩陣就爆炸了.後來找了找其他替代方案,找到了一個叫做SMO的演算法[2],他是使用軼代法的方式來代替掉大量的矩陣運算,並能夠保證運算的正確性,看到這個的時候,覺得發明這個的人根本是天才!後來我採用的方式是簡易版的SMO[3],在演算法上比原本論文寫得更好懂,超推薦!把SMO寫好後,實際跑的感覺超棒的,it works!(拿iris data試跑有90%up準確率)而且沒想到整個演算法也才不到300行,心情超好.
經過SVM的摧殘後,寫決策樹就輕鬆多了,只要補好統計學的基礎知識,像是binominal distribution,就能寫出一個C4.5的node,但後來發現決策樹在決定像double/float型別的資料上範圍,沒這麼好用(主要是我文獻和資料的搜集還不夠多,目前看到的範例都是字串資料當教材),所以目前就只拿它來玩字串資料的分類了,像是分類MES上面的資料.
目前是把SVM拿來推論新增的製程參數的好壞,不過由於累積的樣本數還不夠多,所以還沒有一個明顯趨勢出現.也許根本沒趨勢也有可能,或是資料量大起來後發現自己寫的是錯的也難說.
沒想到當初無心參與python spark課程,找過的資料以及學到的ML知識,會真的應用到我工作的領域上,無心插柳呀.算是一個奇特的經驗,在這跟大家分享~哈.
參考資料
[1]https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/tutorials/MIT6_034F10_tutor05.pdf
[2]http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.43.4376&rep=rep1&type=pdf
[3]http://cs229.stanford.edu/materials/smo.pdf
同軸度 Coaxiality
同軸度和同心度是兩個非常容易搞混的幾何公差. 同軸度的符號如下: 跟正位度的符號是一樣的! 有這種設定,主要是它的定義和正位度的使用方法很像,反而跟同心度沒這麼相似. 首先來個範例: 由於這個不是繪圖軟體做的,只是示意用,不合工程圖規範的部分還請包涵. 這個是...

-
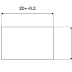 正位度(TRUE POSITION) 正位度在幾何公差上的定義(作者自己的定義)是標明一個特徵(通常是圓柱狀物體或圓柱狀孔位)的位置之容許公差帶,和一般的公差表示法有所不同,一般常見的尺寸公差(圖一) 圖一 其可變動範圍長寬各為+-0.2,所以他的公差帶會是一個矩...
正位度(TRUE POSITION) 正位度在幾何公差上的定義(作者自己的定義)是標明一個特徵(通常是圓柱狀物體或圓柱狀孔位)的位置之容許公差帶,和一般的公差表示法有所不同,一般常見的尺寸公差(圖一) 圖一 其可變動範圍長寬各為+-0.2,所以他的公差帶會是一個矩... -
 同軸度和同心度是兩個非常容易搞混的幾何公差. 同軸度的符號如下: 跟正位度的符號是一樣的! 有這種設定,主要是它的定義和正位度的使用方法很像,反而跟同心度沒這麼相似. 首先來個範例: 由於這個不是繪圖軟體做的,只是示意用,不合工程圖規範的部分還請包涵. 這個是...
同軸度和同心度是兩個非常容易搞混的幾何公差. 同軸度的符號如下: 跟正位度的符號是一樣的! 有這種設定,主要是它的定義和正位度的使用方法很像,反而跟同心度沒這麼相似. 首先來個範例: 由於這個不是繪圖軟體做的,只是示意用,不合工程圖規範的部分還請包涵. 這個是... -
 同心度和正位度都是幾何公差的一種,同心度的定義(作者自己的定義),以參考圓的中心點為基準點,所量測圓的中心點必須落在基準點為圓心的特定直徑的範圍內。 用圖來解釋比較快: 同心度的符號如下, 由於同心度也得需要基準作為比對,因此在符號後面會註記所對應的基準特徵. 下圖是...
同心度和正位度都是幾何公差的一種,同心度的定義(作者自己的定義),以參考圓的中心點為基準點,所量測圓的中心點必須落在基準點為圓心的特定直徑的範圍內。 用圖來解釋比較快: 同心度的符號如下, 由於同心度也得需要基準作為比對,因此在符號後面會註記所對應的基準特徵. 下圖是...
沒有留言:
張貼留言